요새 ChatGPT가 핫 하다.
Transformer에서 발전한 NLP 모델 중 가장 유명한 모델은 BERT와 GPT다. GPT 모델은 현재 4.0 버전까지 개발되었고, 현재 우리가 사용하는 ChatGPT는 GPT3.5 모델을 기반으로 한다.
GPT3.0 버전에서 fine-tuning을 지원하는 모델은 "ada", "curie", "babbage", "davinci" 이며, 아쉽게도 ChatGPT의 근간인 text-davinci-003은 fine-tuning에 사용할 수 없다.
다만 ChatGPT 의 공개 API를 사용해서 Custom한 메세지를 생성하고자 Prompt 테스트를 해 보았다.
Prompt 만으로도 내가 원하는 메세지를 출력할 수 있었지만,
메세지의 종류가 다양해질 수록 Prompt의 양이 많아져서 서비스로 사용하기에는 적합하지 않았다.
그래서 davinci 모델의 fine-tuning 테스트를 진행해 본다
[테스트환경]
- OS : Windows 10
- Anaconda 4.13
- Python 3.9
- Pytorch 2.0
- CUDA 11.7
- cudnn 8.4.1
2023.04.07 기준으로 Pytorch 2.0은 Windows 환경에서 Python 3.7-3.9 버전만 지원하고 있다.
테스트 진행을 위해 예전에 구성한 개발환경을 사용하려 했더니 Libs 버전 충돌이 생겨서 새로 테스트 환경을 구성했다.
[알고리즘] 로컬 개발 환경 구축 #1
머신러닝과 딥러닝 알고리즘을 활용하는 방법과 알고리즘을 탑재한 AI모듈을 개발하는 방법을 정리한다. AI모듈 개발에 필요한 구성 요소를 나름대로 정리해 보았다. AI 모델 개발을 위한 구성요
jarikki.tistory.com
1. OpenAI 환경 설치
Anaconda 가상환경에 openai 설치는 매우 간단하다. (pip으로도 설치 가능)
python-dotenv Lib는 openai 엑세스에 필요한 Secret Key나 모델명 등 외부 변수 활용을 위해 미리 설치한다.
conda install -c conda-forge openai
conda install -c conda-forge python-dotenv
2. davinci 모델 fine-tuning
2023.04.07 기준 OpenAI에서 fine-tuning을 지원하는 모델은 "ada", "curie", "babbage", "davinci" 가 있다.
"ada"가 가장 가벼운 모델이지만,
ChatGPT에 가장 가까운 모델인 "davinci" 모델을 fine-tuning 한다.
(참고로 fine-tuning에 비용이 발생하기 때문에 간단한 테스트를 위해서는 "ada"를 사용해도 좋을 듯 하다)
fine-tuning 수행 단계는 대략적으로 아래와 같다

[프롬프트 데이터 작성]
이 단계는 모델을 학습시킬 데이터를 작성하는 단계다.
학습 데이터는 "prompt"와 "completion" 영역으로 나누어진다.
prompt 는 모델에 입력으로 받을 데이터, 즉 사용자 질문이나 요청 등의 질의 내용으로 구성하고,
completion은 모델의 출력 데이터를 사용자가 원하는 형태로 정의하면 된다.
특정 지표를 입력하면 자연스러운 메세지를 출력하는 모델로 fine-tuning 할 수 있을까?
먼저 테스트를 위해 다음과 같이 학습 데이터를 작성했다.
물론, 아래는 예시고 실제로는 1000개의 row를 가진 데이터 셋을 작성했다.

[openai 데이터 생성]
이 단계는 앞에 작성한 학습 데이터를 OpenAI 모델 학습 규격에 맞도록 변경하고, 검증하는 단계다.
사람이 직접 검증하는 것은 아니고, OpenAI Tool을 이용하면 된다.
아래와 같이 데이터 생성/검증 단계를 거치면, 앞으로 진행될 fine-tuning에 필요한 몇 가지 중요한 정보를 알려준다.
# 실행 명령어
openai tools fine_tunes.prepare_data -f [프롬프트 파일명]
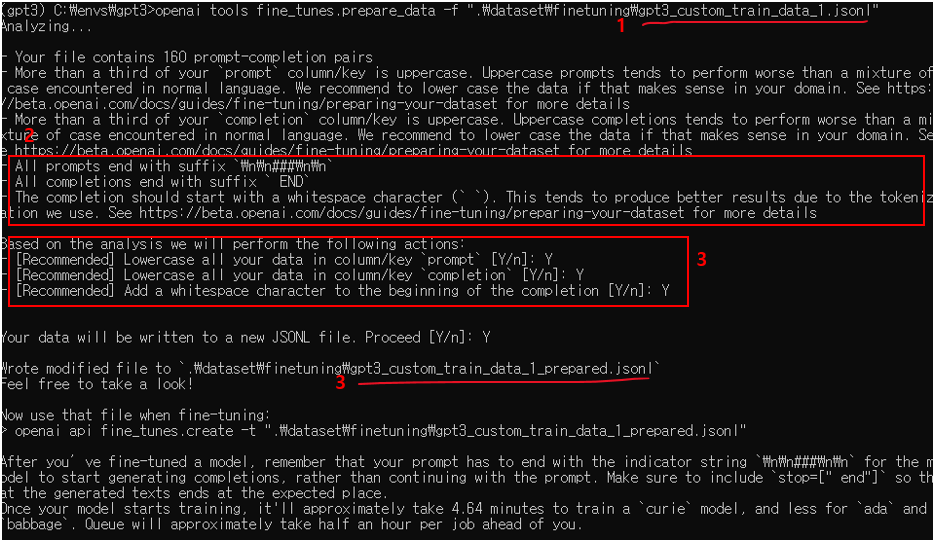
- OpenAI Tool로 검증할 학습 데이터 파일명(내가 작성한)
- 각 Prompt의 마지막은 "\n\n###\n\n" 문자열로 인식되고, Completion의 마지막은 " END"(space 포함)로 인식됨
- Prompt와 Completion의 모든 문자열을 "소문자"로 변경함
- OpenAI Tool로 검증이 완료된 학습 데이터 파일명(내가 작성한 파일에 "prepared"가 붙여져 새로운 파일이 생성됨)
[Custom 모델 생성]
이 단계는 검증이 완료된 학습 데이터를 이용하여 fine-tuning할 Custom 모델을 생성하는 단계다.
아래 명령어를 실행한다.
# 실행 명령어
openai --api-key [OpenAI에서 받은 SecretKey] api fine-tunes.create -t [검증 완료된 학습 데이터] -m davinci --sufix [생성될 모델에 포함하고 싶은 string]

- fine-tuning에 사용할 데이터-셋 ID
- fine-tuning을 진행할 내부 Task ID
- fine-tuning 진행 시 비용(유료임)
- fine-tuning을 진행하기 위한 대기열 번호
"1"번과 "2"번은 fine-tuning 진행 중 또는 완료 후 결과 확인을 위해 필요하므로 따로 기입해 둔다
fine-tuning이 완료되면 다음과 같은 결과가 출력된다.
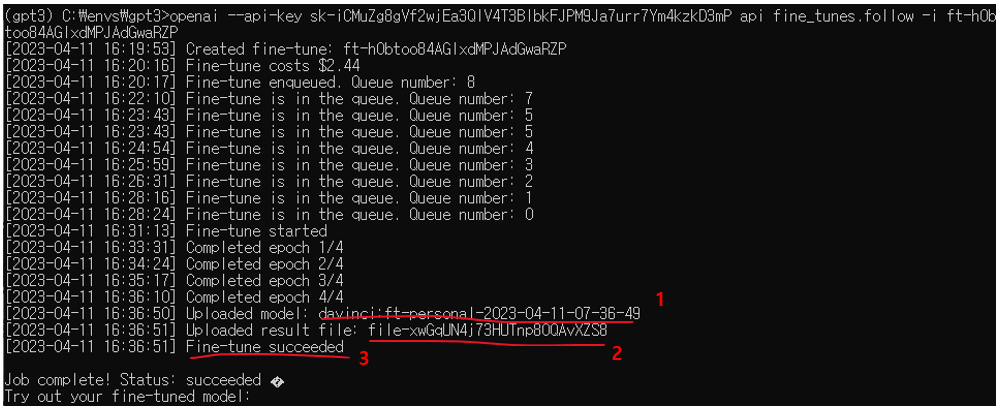
- fine-tuning 후 생성된 사용자 모델명
- fine-tuning 결과를 저장한 파일ID
- 수행결과
"1"과 "2번" 역시 나중에 사용해야 하므로 따로 기입해 둔다.
[결과확인]
fine-tuning이 실행된 모델의 학습 품질을 확인할 수 있다.
# 실행 명령어
openai --api-key [OpenAI에서 받은 SecretKey] api fine-tunes.result -i [fine-tuning Task ID]

결과적으로 총 641 step이 진행되었고, 손실값=0, 정확도=100% 가 나왔다.
실화냐?
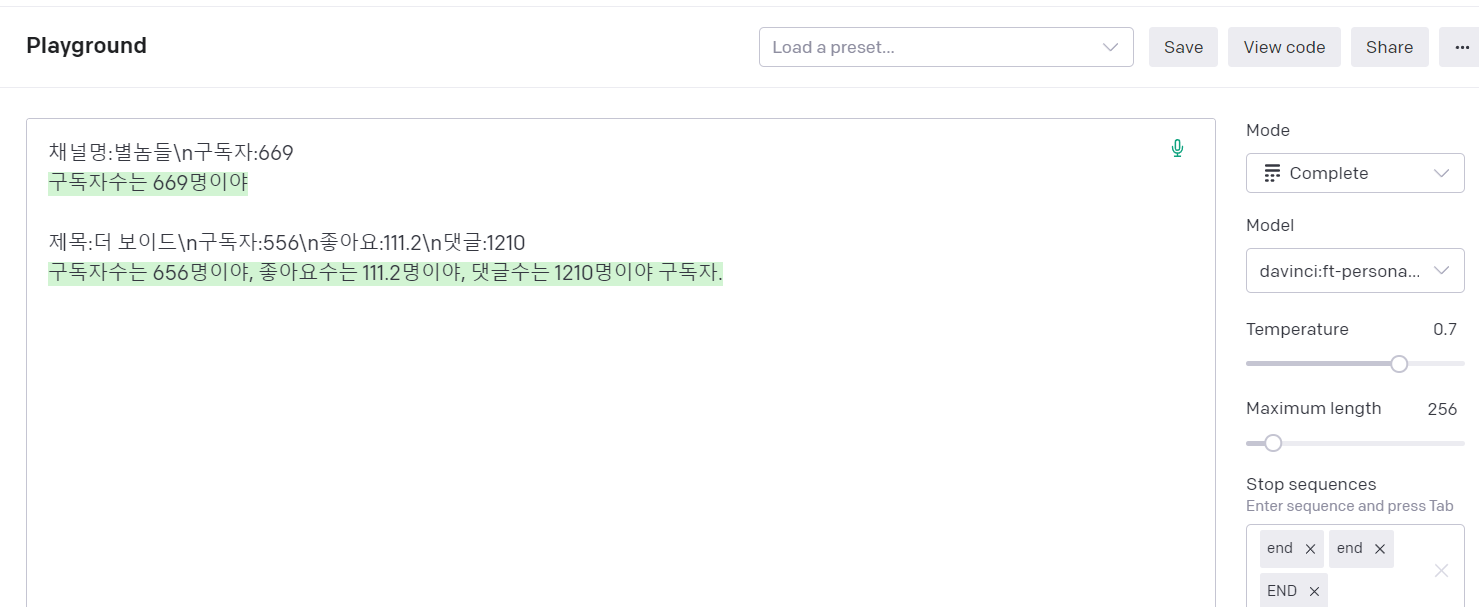
어쨌든 나만의 GPT 모델을 생성했으니, Python 프로그램을 작성해서 검증해 보자.(물론, OpenAI 포달이 제공하는 PlayGround를 사용해도 됨)
[fine-tuning 명령어 정리]
- 데이터 생성 : openai tools fine_tunes.prepare_data -f "파일명"
- 모델 생성 : openai --api-key "SecretKey" api fine_tunes.create -t "데이터파일명" -m "모델명"
- 진행상태 확인 : openai --api-key "SecretKey" api fine_tunes.follow -i "fine-tuning Task ID"
- 학습 결과 확인 : openai --api-key "SecretKey" api fine_tunes.result -i "fine_tuning Task ID"
- 커스텀 모델 목록 : openai --api-key "SecretKey" api fine_tunes.list
- 학습 중지 : openai --api-key "SecretKey" api fine_tunes.cancle -i "fine_tuning Task ID"
- 커스텀 모델 삭제 : openai --api-key "SecretKey" api fine_tunes.delete -i "fine-tuning된 모델 ID"
Fine-tuning 이 완료되었으니, 이제 간단한 프로그램을 만들어야겠다.
[알고리즘] ChatGPT - fine tuning #2
겨울나기 바캉스
망각으로 부터의 자유와 새로운 도전을 위한 나만의 기억의 궁전
jarikki.tistory.com
'ML & AI > Algorithm' 카테고리의 다른 글
| [알고리즘] ChatGPT - API 활용 #1 (0) | 2023.03.22 |
|---|---|
| [알고리즘] 임베딩과 손실함수 선택하기 #4 (0) | 2022.10.05 |
| [알고리즘] Merge를 통한 데이터 Filtering & Mapping #3 (0) | 2022.09.30 |
| [알고리즘] 알고리즘을 활용한 AI모듈 개발 방법 #2 (0) | 2022.09.23 |



